在业务系统功能中,不难见到上传Excel文件批量处理的场景,由于Excel文件的复杂性,存在很多容易出问题的可能性。
1 复现
我们通过一个简化的SpringBoot工程来演示有问题的代码、如何通过Eclipse Memory Analyzer工具分析堆转储文件,来定位到问题代码。
工程代码excel-oom.zip:
.
├── pom.xml
├── readme.md
├── src
│ └── main
│ └── java
│ └── demo
│ └── exceloom
│ └── DemoExcelOomApplication.java
├── test.xlsx
在DemoExcelOomApplication.java中是我们关注的重点,使用Apache POI框架解析输入流,然后读取第一张表的每一行:
@RequestMapping(value = "import", method = RequestMethod.POST)
public ResponseEntity<String> importDataByPoi(MultipartFile file) throws Exception {
Workbook workbook = WorkbookFactory.create(file.getInputStream()); // poi解析输入流
Sheet sheetOne = workbook.getSheetAt(0);
for (int i = 1; i <= sheetOne.getLastRowNum(); i++) {
Row row = sheetOne.getRow(i);
// 读取每一行
}
return new ResponseEntity<>("ok", HttpStatus.OK);
}
需要使用JDK8构建和运行
构建:
mvn clean package
为了演示,这里将JVM最大堆内存限制为64m,运行:
java \
-server -Xms64m -Xmx64m \
-XX:+HeapDumpOnOutOfMemoryError \
-jar target/excel-oom-0.0.1-SNAPSHOT.jar
工程包里已含有一个Excel文件,行数是148269:

使用Excel文件调用接口,其中Excel:
curl --location 'localhost:8080/import' --form 'file=@"test.xlsx"'
不出意外的话,控制台将会提示OOM已发生,JVM将会在当前目录生成堆转储文件,例如java_pid27718.hprof,其中27718是进程ID:
2023-05-28T16:45:38.821+08:00 INFO 27718 --- [nio-8080-exec-2] o.s.web.servlet.DispatcherServlet : Completed initialization in 1 ms
java.lang.OutOfMemoryError: Java heap space
Dumping heap to java_pid27718.hprof ...
Heap dump file created [94201075 bytes in 0.246 secs]
Exception: java.lang.OutOfMemoryError thrown from the UncaughtExceptionHandler in thread "Catalina-utility-2"
Exception: java.lang.OutOfMemoryError thrown from the UncaughtExceptionHandler in thread "http-nio-8080-Poller"
Exception in thread "Catalina-utility-1" java.lang.OutOfMemoryError: Java heap space
2023-05-28T16:49:05.855+08:00 ERROR 27718 --- [nio-8080-exec-5] o.a.c.c.C.[.[.[/].[dispatcherServlet] : Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception [Handler dispatch failed: java.lang.OutOfMemoryError: Java heap space] with root cause
从日志里可以发现OOM的线程是nio-8080-exec-5,这里是由于日志配置限制了展示的线程名称的长度。更多的信息需要借助Eclipse Memory Analyzer来获取了。
2 分析
到mat官网下载,解压之后需要给mat分配足够的堆内存,避免分析过程卡顿,编辑MemoryAnalyzer.ini:
-startup
../Eclipse/plugins/org.eclipse.equinox.launcher_1.6.400.v20210924-0641.jar
--launcher.library
../Eclipse/plugins/org.eclipse.equinox.launcher.cocoa.macosx.x86_64_1.2.700.v20221108-1024
-vmargs
--add-exports=java.base/jdk.internal.org.objectweb.asm=ALL-UNNAMED
-Xmx4g #添加
-Xms4g #添加
-Dorg.eclipse.swt.internal.carbon.smallFonts
-XstartOnFirstThread
保存后启动,打开示例工程生成的堆转储文件:
解析完成之后,选择Leak Suspects Report > Finish
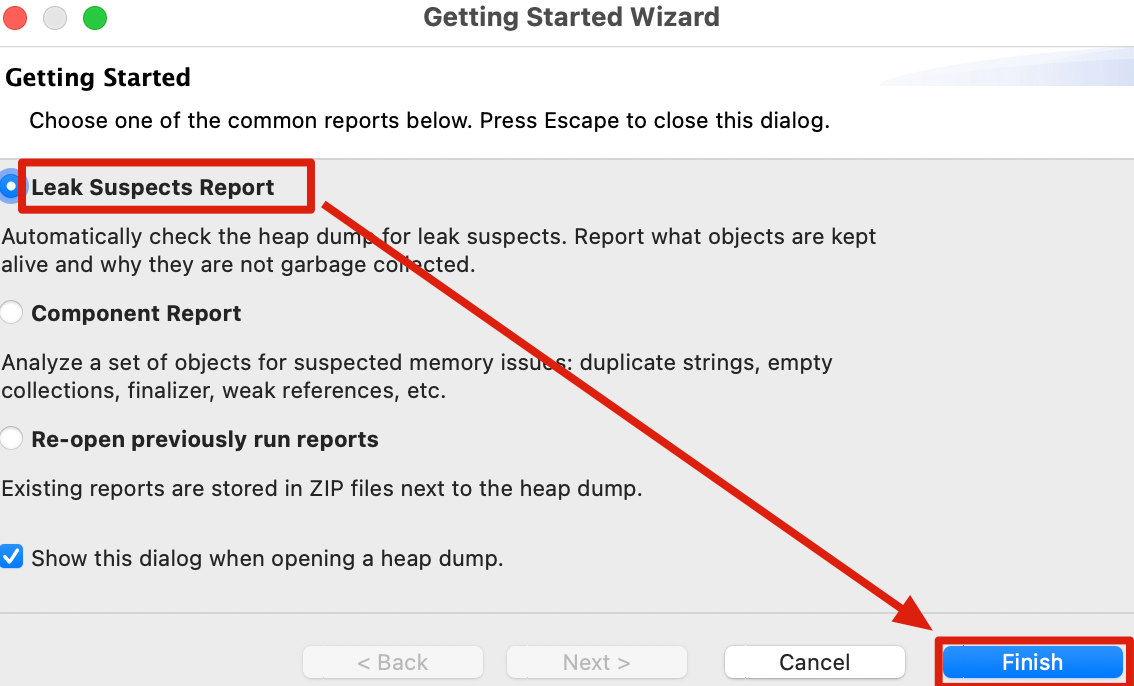
得出的问题嫌疑只有一个,占用了35.9MB的内存。因为实例代码比较简单,所以只有一个嫌疑,但是在实际的复杂场景下中可能会出现多个嫌疑,都需要观察一下
我曾在一个OOM中见过一个用户产生的两个相同的并发操作,占据了分析结果的Problem Suspect 1和2
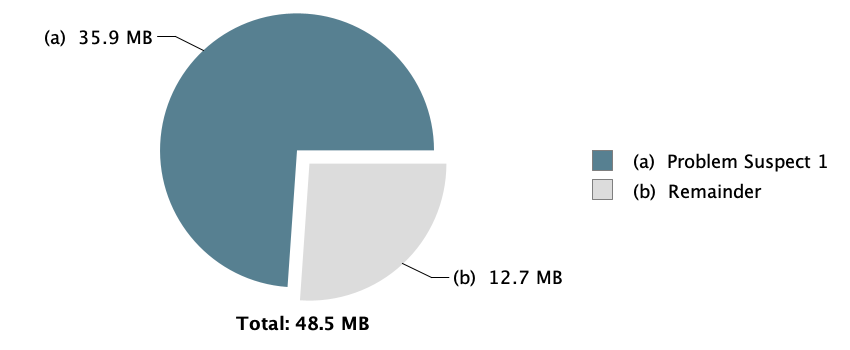
在Problem Suspect 1中发现线程是http-nio-8080-exec-5,与我们在日志中看到的一致。
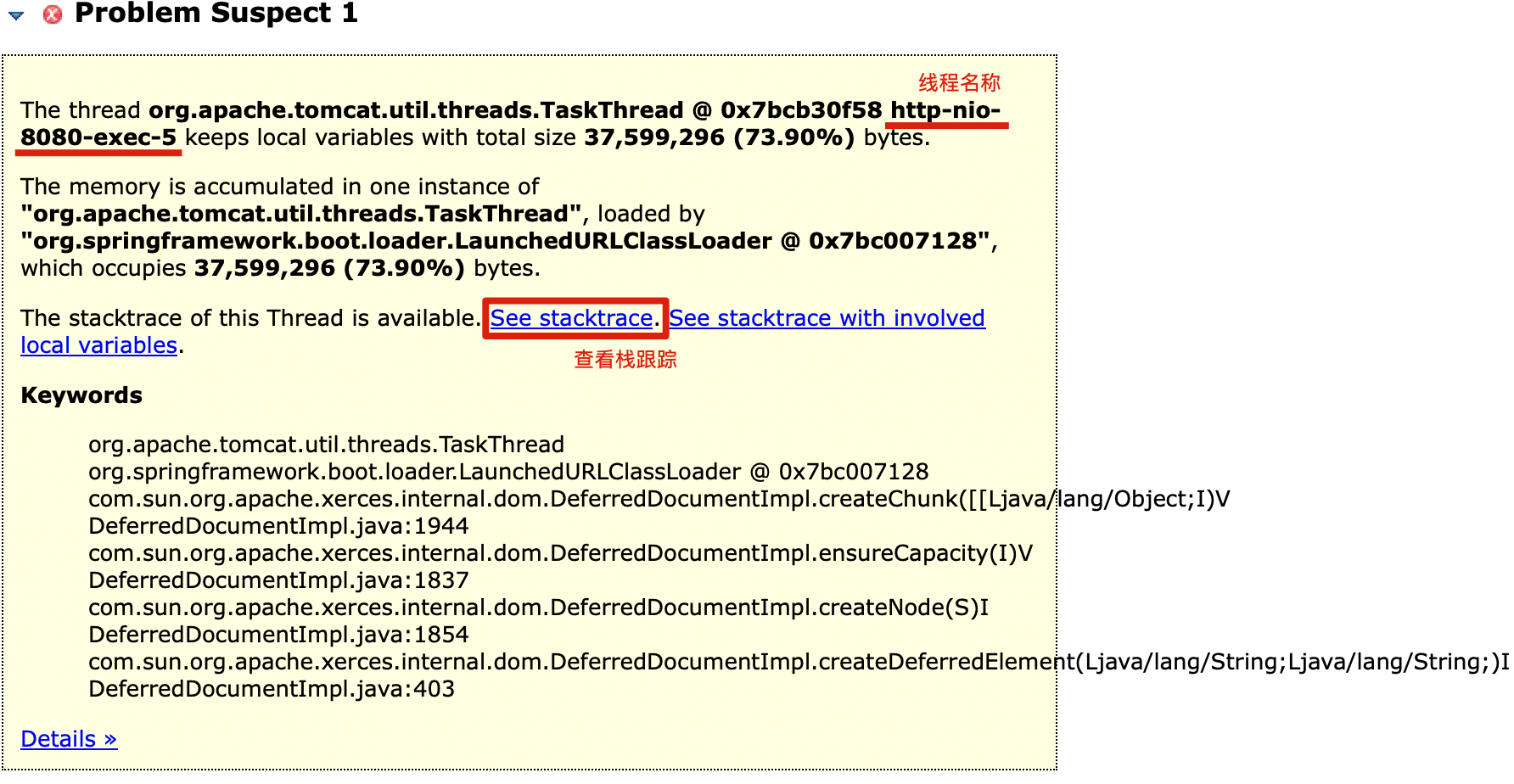
点击See stacktrace,查看栈跟踪,从上往下看,可以找到第一个业务代码,既是问题所在了。
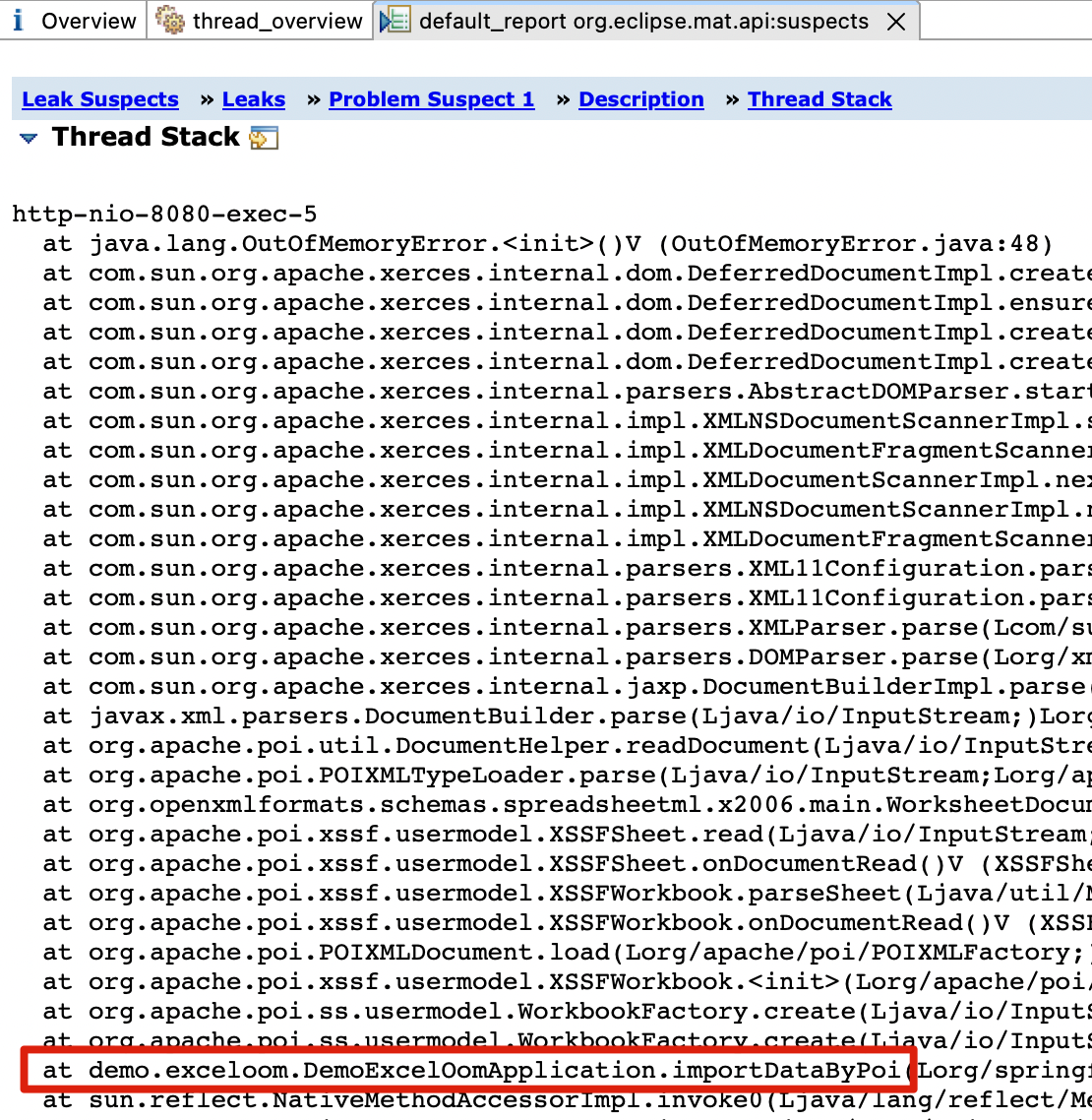
当然这个步骤也不是必须人眼一行一行地看,可以借助Intellij IDEA快速定位到业务代码:首先复制栈跟踪的文本,再切换到IDEA,点击菜单Code>Analyze Stack Trace or Thread Dump>OK
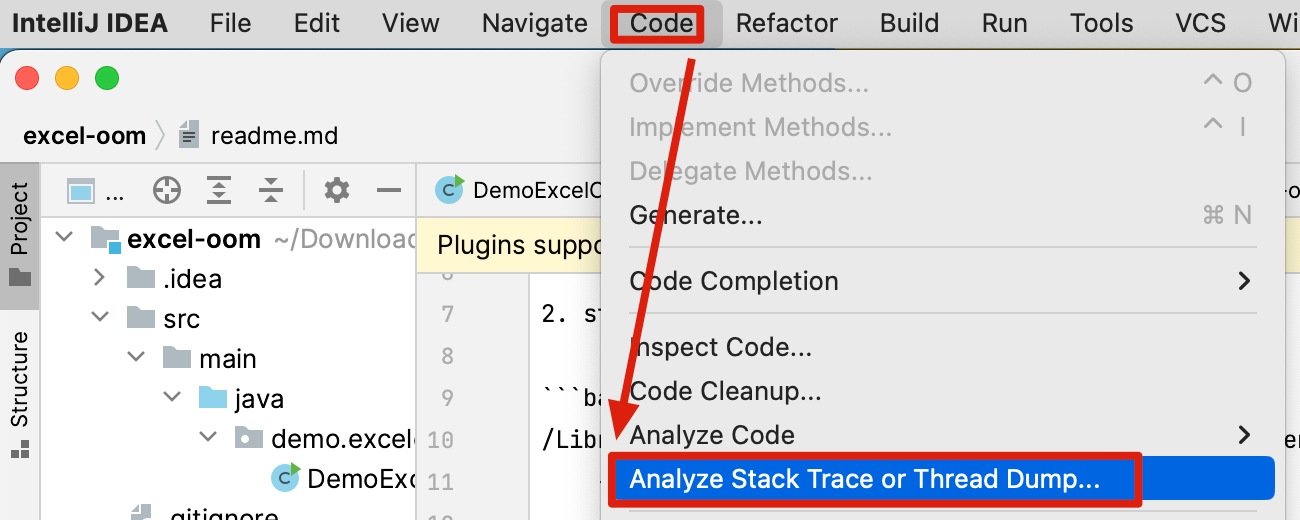
蓝色字体就是业务代码了,点击可以跳转,是不是比肉眼看更快?

至此找到了导致OOM的业务代码,可以甩锅了Win+L锁屏下班,看起来也无可厚非:解析后读取,但如果继续深入跟POI的源码的话,会发现是要将全部内容都加载到内存解析完成再返回,对于JVM堆内存无法解析输入Excel的行数规模时,OOM就会发生。
那么有哪些思路可以避免这种情况的发生呢?
3 思路
3.1 easyexcel
第一个思路当然是换坑,换一个框架,比如alibaba的easyexcel,引入依赖:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>2.2.7</version>
</dependency>
使用以下代码来读取:
@Data
public static class ExcelRow {
@ExcelProperty("name")
private String name;
@ExcelProperty("id")
private String id;
}
@RequestMapping(value = "import-by-easyexcel", method = RequestMethod.POST)
public ResponseEntity<String> importDataByEasyExcel(MultipartFile file) throws Exception {
final List<ExcelRow> objects = EasyExcel.read(file.getInputStream(), ExcelRow.class, new AnalysisEventListener<ExcelRow>() {
private int count = 0; // 行数
private final static int maxCount = 100; // 常量:最大行数
@Override
public void invoke(ExcelRow data, AnalysisContext context) {
count++; // 增加行数
}
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
}
@Override
public boolean hasNext(AnalysisContext context) {
return count <= maxCount;// 行数不能大于最大行数
}
}).sheet(0).doReadSync();
return new ResponseEntity<>("ok,rows:" + objects.size(), HttpStatus.OK);
}
以同样的JVM参数启动后,发起请求:
curl --location 'localhost:8080/import-by-easyexcel' --form 'file=@"test.xlsx"'
得到响应:
ok,rows:100
看起来很优雅,但是对于遗留代码侵入性很大,有没有更黑魔法优雅的?
3.2 常量空间复杂度的解析行数
Excel常见有两种格式,xls和xlsx,维基百科抄一抄
Microsoft Excel up until 2007 version used a proprietary binary file format called Excel Binary File Format (.XLS) as its primary format. Excel 2007 uses Office Open XML as its primary file format, an XML-based format that followed after a previous XML-based format called “XML Spreadsheet” (“XMLSS”), first introduced in Excel 2002.
因为xlsx是比xls更新的格式,着重关注一下:
The default Excel 2007 and later workbook format. In reality, a ZIP compressed archive with a directory structure of XML text documents. Functions as the primary replacement for the former binary .xls format, although it does not support Excel macros for security reasons. Saving as .xlsx offers file size reduction over .xls
也就是说xlsx使用zip打包了xml文本,对于上文的test.xlsx文件,解压之后内容结构如下:
.
├── [Content_Types].xml
├── _rels
├── docProps
│ ├── app.xml
│ └── core.xml
└── xl
├── _rels
│ └── workbook.xml.rels
├── sharedStrings.xml
├── styles.xml
├── theme
│ └── theme1.xml
├── workbook.xml
└── worksheets
└── sheet1.xml
观察xl/worksheets/sheet1.xml的末尾,可以发现倒数两行的内容:148168和148169
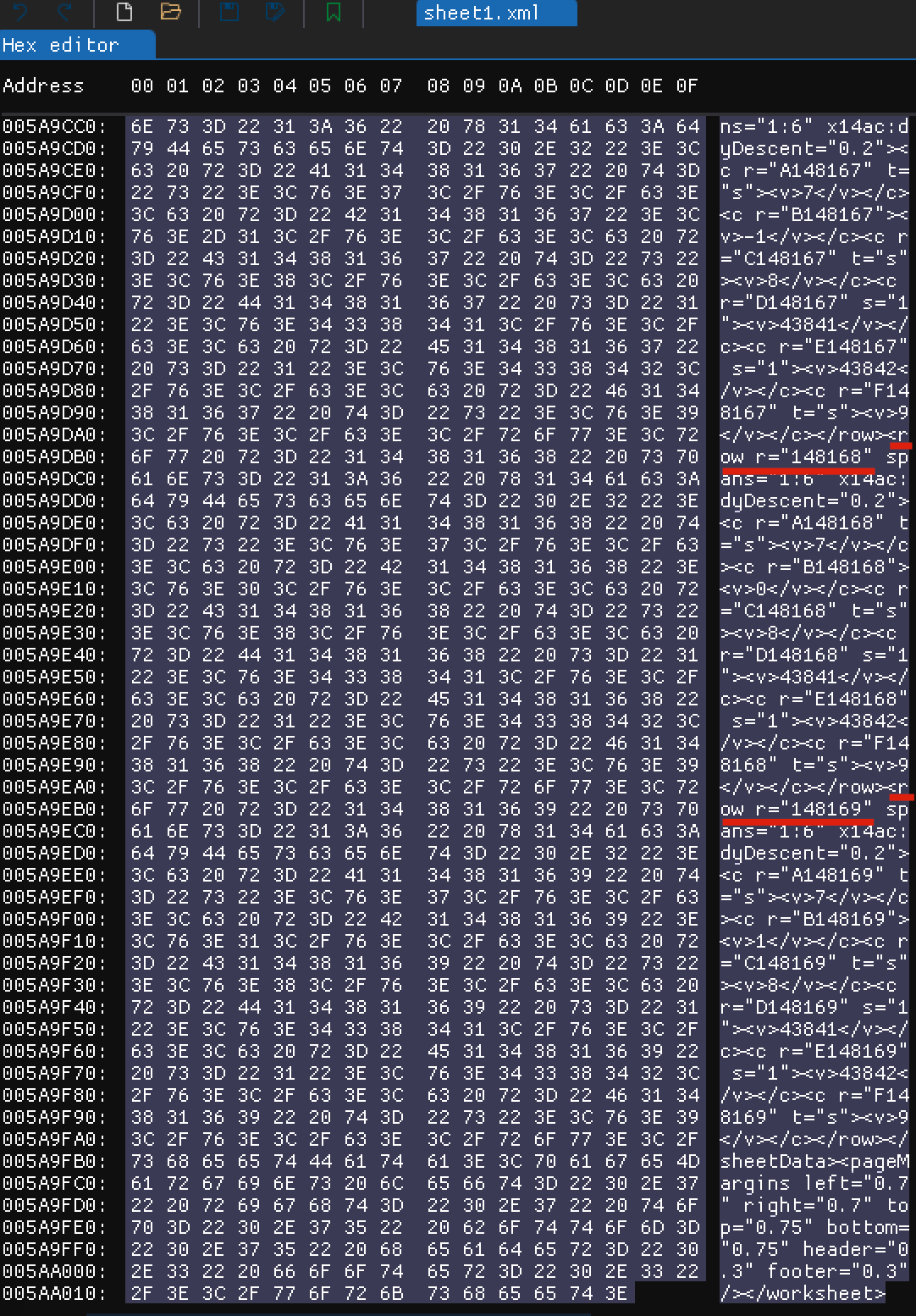
也就是说:在xml中,行是按照顺序依次分布的,那么我们可以从xml文件的末尾往前读取文件,在buffer内搜索字符串<row r=,若未搜索到,则继续读取后拼接到原buffer,直到搜索到为止。搜索到之后就能够解析到最后一行的编号,也就是行数。
这种机制的时间、空间复杂度受列数影响,不受行数影响,使用Excel的各个场景里,列数都是是固定的,所以这种算法适用于我们这里的场景。
使用以上思路可以实现一个工具方法拿到Excel的行数,业务代码里使用这个工具方法,在遗留代码解析Excel之前(例如上文的POI),拿到行数并进行断言:不能超过限定行数。
这个工具方法大致实现步骤如下:
- 实现一个InputStream类NeverCloseInputStream,close方法内不做任何操作
- 使用NeverCloseInputStream包装
org.springframework.web.multipart.MultipartFile#getInputStream方法返回的输入流,并传入zip4j框架解压缩到临时文件。原因是避免关闭流之后影响遗留代码里对输入流的读取。 - 定位到目标sheet的xml,使用
java.io.RandomAccessFile实现对xml的随机(从末尾往前)读取 - 使用1kb的buffer读取文件末尾,搜索目标的字节数组(即<row r=),搜索不到则继续读取后拼接到原有buffer后继续搜索,直到搜索到为止
- 搜索到字节数组后,拿到下标开始到下一个"出现的内容,解析成int,即得到行数